IBMにおけるDITAの取り組み
2008年04月01日作成
1page 2page
吉野 徹夫 氏【日本アイ・ビー・エム株式会社】
最近注目を集めているXMLベースのアーキテクチャーであるDITA(Darwin Information Typing Architecture)。「
トピック指向の次世代文書記述言語-DITA」の記事ではDITAの概要について扱いましたが、DITAを実際使用することでどのようなメリットがあるのでしょうか。すでにDITAを利用した文書作成システムを数年にわたり運用されている、日本アイ・ビー・エム株式会社 ナショナル・ランゲージ・サポート担当の吉野 徹夫氏にお話を伺ってきました。
IBMではいつごろからDITAを使用されていますか。また、DITAを採用するまでの経緯を教えていただけますか。
2002年からDITAを使い始めました。IBMでは以前からマークアップベースの文書作成システムを使っていました。最初はGML(General Markup Language)ベースのものからスタートしSGML(Standarized General Markup Language)ベースでIBM独自のDTDを使ったものへと移行し、そして、現在のDITAを使うようになりました。
もともとGMLは文書を作成するためのもので、これを使用すると、同じコンピュータのマニュアルをいくつかの国で出版する際に、言語が異なっていても同じスタイルで統一されたマニュアルを作ることができました。その後、出力先の種類の増加(たとえば、印刷物とオンライン情報を同じファイルから作成する)をサポートするために、情報の再利用性などを考え、文書情報を、レイアウトと論理構造に分ける必要ができました。そのため、10年以上前にSGMLを採用しました。しかし、GMLからSGMLに移行する際に、すべてのドキュメントを、レイアウトと論理構造に分けることができませんでした。また、IBMでは、IBM独自のSGMLである、IBMIDDocを使っていますが、IBMIDDocは、GMLで作成されたスタイルを移行することを重視していたためにDTDが独自の複雑なもので、非常にIBM色の濃いものでした。
それらを改善するために、つまり、以前からの目標であった、論理をレイアウトから完全に独立させることと、今後、他のコミュニティとも情報の交換が必要になることを考え、独自のものではなく、今ではOASIS標準であり、オープンな技術であるDITAへ移行しました。
DITAを使用するメリットは何でしょうか。
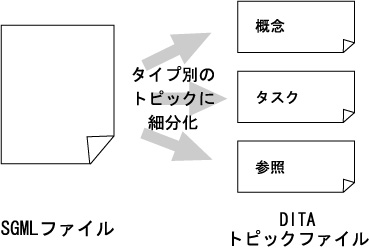
DITAを使用する一番大きなメリットは、文書の再利用が容易になることです。いままでの、SGMLの場合は、一つ一つのファイルが結構大きかったために、再利用するというのは非常に難しいことでした。DITAでは「概念」「タスク」「参照」といった小さくて自己完結したトピックに文書を分けます。そのように分けることによって、それぞれのコンポーネント、情報の単位が小さくなりましたので、文書の再利用が容易になりました。
また、情報とレイアウトが独立しているので表示形式を変更する面でもとても優れています。例えば、DITAを使うことによって、同じ文書から、PDFやオンラインヘルプを作ることもできますし、文書の一部を、PII 1に組み込むこともできます。
GMLやSGMLの場合には、成果物を作成するために利用するファイルの情報などがソースファイルの内部に記述されていました。ところが、DITAの場合にはソースファイルの内部ではなく、ditamapという文書を構成するトピックを記述したXMLファイルによってコントロールできるのです。マップ文書が様々なトピックを配置して形式の異なる成果物を作り上げます。この点はGMLやSGMLとDITAの大きな違いだと思います。
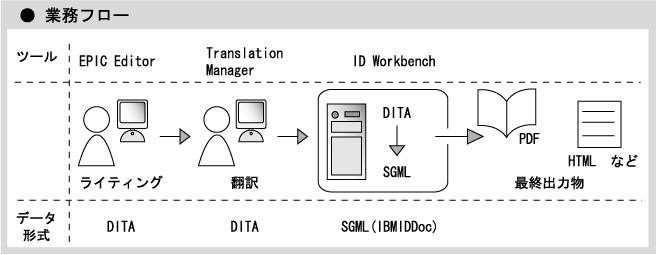
ライティングから最終成果物にいたる業務フローを教えてください。
ライティングには、タグの詳細を意識しないで編集できるエディタ、EpicEditorを使っています。IBMではPDFや、Windowsヘルプ、XHTMLなど、様々な形式の出力物を作るID Workbenchと呼ぶツールがあります。翻訳したものを、それらのツールを使って最終出力物へ変換しています。
DITAへの移行に伴って、マークアップが変わるというのは、大きなことですが、以前から同じエディタを使っているのでマークアップという観点から言うと、ライターはDITAのタグをあまり意識せずに書くことができています。ただ、コンポーネントごとに分割し、情報の単位を小さくする必要があるので、以前に比べ、タスクオリエンテッドの書き方ではなく、ファンクションオリエンテッドの書き方が多くなっていると思います。
タスクオリエンテッドというのは、ユーザーが行いたいこと(タスク)をどのように実現できるかという視点で文書を書きますが、それを短いトピックで記述していくことは難しくなります。ですから、DITAに移行するにあたって、ファンクションオリエンテッド、つまりタスクではなく、機能の説明を中心とした文書が増えているように感じます。
将来的にはDITAのファイルそれぞれをコンテンツマネジメントシステムで管理して、そのデータベースから直接、しかもいろいろな切り口で引き出すような形になると思います。そうすることで、より情報の再利用を促進することができるからです。
出力物を作るツールにはどのようなものを使用されていますか?
DITAへ移行する以前の文書は、すべてSGMLベースでしたからSGMLを様々な形式に変換するツールセットである、先ほど申し上げたID Workbenchという独自のツールを使って、最終出力物に変換しています。これによりすべてのドキュメントのスタイルを統一することや、すべての言語について同じ出力結果を得ることができていました。DITAに移行した後も、今まで多くの投資をしてきたプロセスを有効に使いたいと考え、現在はID Workbench内で一度DITAからIBMIDDoc、つまりSGMLに変換して、それから、PDFやWebヘルプという形に変換するプロセスをとっています。これに関しては将来的にはDITA専用になっていくこともあるかもしれませんね。
現在どの程度DITAに移行されているのでしょうか。
インフォメーションにも様々な種類のものがありますが、通常のオンラインヘルプやマニュアルということで考えると現在約50パーセントがDITAに移行しています。
以前からある製品に関してマニュアルが少し改訂されただけの場合は、移行せず、大きな改訂がある場合や新しい製品に関しては積極的にDITAに移行しています。




 【Toy Box:007】FrameMaker 9 新機能紹介 その4 ~ブック機能拡張~
【Toy Box:007】FrameMaker 9 新機能紹介 その4 ~ブック機能拡張~